前言
SmartOS 的diskless booting的架构是它的重要的特性之一,也是我们了解一个操作系统很好的切入点,我这里我们就通过介绍SmartOS的这个特性,以及SmartOS的启动过程来看它是如何实现的?以及SMF在这个启动过程中扮演了什么角色?下面我们来一一介绍。
SmartOS Diskless Booting
SmartOS Diskless Booting实际上是将它的操作系统,安装在了ramdisk上(也就是内存中), 然后直接通过USB/CD/PXE来启动它,那这么做的好处是什么?
- 系统更新简单: 每次重启即可。
- 增加了磁盘的空间: 操作系统本身不占用磁盘空间, 某中程度上也增加了磁盘的性能。
- 增加了安全性:大部分的系统文件是只读的,
/root 和/etc目录每次重启都重置,/usr目录也是只读, 无法添加用户。对SMF服务的修改也是每次都重置。
- 系统稳定性提高: 不会出现操作系统在磁盘,而磁盘坏掉导致整个OS无法启动。
那么SmartOS的global zone上哪些目录是可写的?
Filesystem Size Used Available Capacity Mounted on
zones 2.0T 143M 1.8T 1% /zones
zones/var 2.0T 4.0G 1.8T 1% /var
zones/opt 2.0T 55K 1.8T 1% /opt
zones/usbkey 2.0T 154K 1.8T 1% /usbkey
/usbkey/shadow 1.8T 154K 1.8T 1% /etc/shadow
/usbkey/ssh 1.8T 154K 1.8T 1% /etc/ssh
这里列出的目录为可写, zones是使用了所有磁盘的一个大zpool, SmartOS会在启动的时候创建一些文件系统挂载上去。
SmartOS 启动过程
我们从按下机箱电源按钮说起, 看下图会比较清楚:
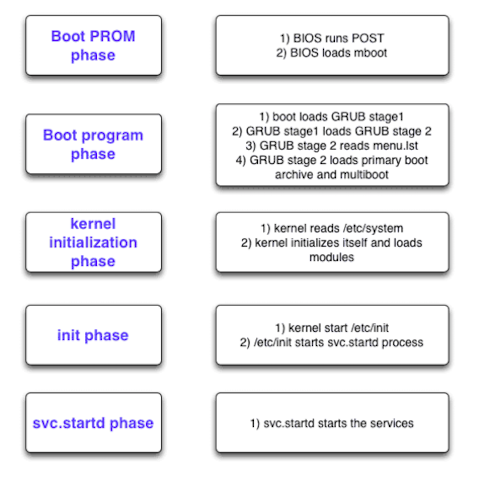
- 当按下机箱上电源键之后,机器会直接执行储存在主板上的BIOS应用程序;
- BIOS检测完硬件之后,去启动主硬盘的引导区的那个引导程序。现在应用的最广泛的引导程序叫做GRUB;
- GRUB会做一些初始化文件系统的活儿,读取一个配置文件(menu.lst),去启动真正想要的内核
(platform/i86pc/kernel/amd64/unix)和boot archive(platform/i86pc/amd64/boot_archive文件);
- 内核在这个时候被载入内存启动了。跟前面步骤的那些应用程序执行完了就把自己杀掉不同,内核不会杀掉自己。它会把你的机器硬件弄成可以共享的形式,后面的应用程序来共享使用;
- 然后内核会启动一个新的应用程序
(/sbin/init, pid=1),来负责启动其他的应用程序。
接着看下图:
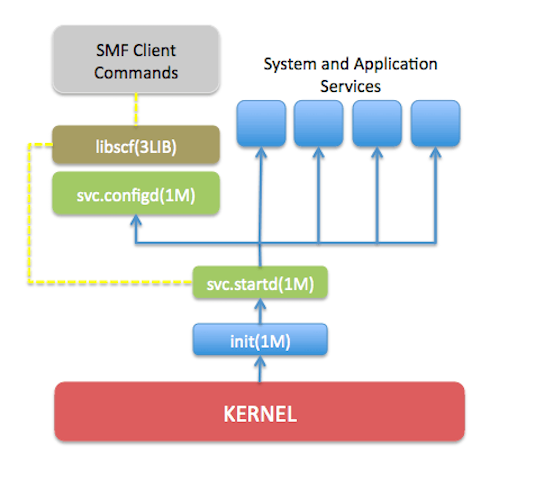
- init服务会启动
svc.startd这个进程,用来启动和停止所有的SMF服务。
到这里Kernerl和boot_archive都已经加载, startd服务启动,我们看下systemfile的挂载情况:
Filesystem Size Used Available Capacity Mounted on
ctfs 0K 0K 0K 0% /system/contract
proc 0K 0K 0K 0% /proc
mnttab 0K 0K 0K 0% /etc/mnttab
swap 43G 984K 43G 1% /etc/svc/volatile
objfs 0K 0K 0K 0% /system/object
bootfs 0K 0K 0K 0% /system/boot
sharefs 0K 0K 0K 0% /etc/dfs/sharetab
以上这些文件系统的挂载由kernel完成。根据细节服务要看illumos源码,比如restarter/boot-config/svc.configd服务等。
到了这里我们必须要说一下SmartOS的运行级别。
SmartOS Run level
SmartOS提供了8个run level,如下:
0 - system running PROM monitor (ok> prompt)
s or S - single user mode with critical file-systems mounted.(single user can access the OS)
1 - single user administrative mode with access to all file-systems.(single user can access the OS)
2 - multi-user mode. Multiple users can access the system. NFS and some other network related daemons does not run
3 - multi-user-server mode. Multi user mode with NFS and all other network resources available.
4 - not implemented.
5 - transitional run level. Os is shutdown and system is powered off.
6 - transitional run level. Os is shutdown and system is rebooted to the default run level.
正常情况下启动SmartOS运行的runlevel是3, 即多用户共享模式。我们可以通过who命令来查看当前的runlevel:
$ who -r
. run-level 3 Jun 10 09:14 3 0 S
当然你还可以通过init命令来切换当前的runlevel,比如你想切换到单用户模式: init s 即可。
对于传统的init服务的启动是按照不同的runlevel去执行对应的/etc/rc?.d/K* and /etc/rc?.d/S* 脚本, ?为运行级别, 这种方式在SmartOS中还是支持的,但主要为了兼容legacy的系统,并不推荐,目前使用的基于SMF的方式。那么是SMF是如何支持runlevel的?
实际上是通过category是milestone的smf来定义runlevel:
/etc/rcS.d => milestone/single-user:default #对应单用户模式
/etc/rc2.d => milestone/multi-user:default #对应多用户
/etc/rc3.d => milestone/multi-user-server:default #对应多用户共享
在了解完SMF服务和runlevel的关系之后我们继续来看SmartOS的启动过程。从前面知道SmartOS默认启动在run level 3上,所以它会先运行完run level s和2的服务。下面我们先来分析run level s模式下smf服务的情况。
SmartOS 启动之: Run Level s
通过如下命令切换到run level s下面:
$ init s
$ svcs |grep milestone #在run level s下面,启动了2个milestone服务
online 9:12:44 svc:/milestone/devices:default
online 9:14:17 svc:/milestone/single-user:default
这里提下/lib/svc/manifest/目录,这个目录中又按照不同的类别分成了若干个子目录, 定义主要的系统依赖的SMF服务。系统启动的时候startd服务会自动的根据依赖去加载这个目录中的SMF服务。
从这里我们看到milestone/devices服务是最先启动的,看看它依赖了什么服务。
svc:/milestone/devices
svc:/system/device/local
svc:/network/datalink-management #网络相关先放一边
svc:/system/filesystem/usr
svc:/system/boot-archive
svc:/system/filesystem/root
svc:/system/device/mpxio-upgrade #这个IO multipath的依赖是optional的
svc:/system/scheduler
svc:/system/filesystem/root
这里通过svcs -d命令整理出来了依赖关系,我们看到了它最终依赖于filesystem/root这个服务, 那这个服务在启动的时候干了什么事情?通过/lib/svc/manifest/system/filesystem/root-fs.xml文件的定义找到/lib/svc/method/fs-root运行脚本,关键代码:
/sbin/mount -F ufs -o remount,rw,nologging /devices/ramdisk:a /
/usr/sbin/lofiadm -X -a /usr.lgz
/sbin/mount -F ufs -o ro /devices/pseudo/lofi\@0:1 /usr
#
# Update kernel driver.conf cache with any additional driver.conf
# files found on /usr, and device permissions from /etc/minor_perm.
#
/usr/sbin/devfsadm -I -P
libc_mount
实际上是将ramdisk上的文件系统mount到/, 通过lofiadm将usr.lgz文件(可执行文件和lib)做成块设备mount到/usr目录(read-only),最好将libc的标准库mount上来, 结果如下:
Filesystem Size Used Available Capacity Mounted on
/devices/ramdisk:a 262M 240M 22M 92% /
/devices/pseudo/lofi@0:1
432M 377M 56M 88% /usr
/usr/lib/libc/libc_hwcap1.so.1
432M 377M 56M 88% /lib/libc.so.1
ctfs 0K 0K 0K 0% /system/contract
proc 0K 0K 0K 0% /proc
mnttab 0K 0K 0K 0% /etc/mnttab
swap 43G 984K 43G 1% /etc/svc/volatile
objfs 0K 0K 0K 0% /system/object
bootfs 0K 0K 0K 0% /system/boot
sharefs 0K 0K 0K 0% /etc/dfs/sharetab
接着我们往上追踪,找到_system/boot-archive_服务,/lib/svc/manifest/system/boot-archive.xml对应脚本/lib/svc/method/boot-archive看关键代码:
/sbin/bootadm update-archive -vnC 2> /dev/null
这里只是更新了一下boot_archive, 我们接着看_filesystem/usr_服务/lib/svc/manifest/system/filesystem/usr-fs.xml 脚本/lib/svc/method/fs-usr, 关键代码:
mount /dev/fd
if smf_is_globalzone; then
# svc.startd makes a backup of the repo on boot. Since this is a
# live-image, the backup takes up an unnecessary 4MB in memory, so remove
# it now.
rm -f /etc/svc/repository-*
fi
文件系统fd挂载到/dev/fd, 并在内存删除不必要的备份。 到这里_milestone/devices_服务启动完成, 看看系统中mount了什么:
Filesystem Size Used Available Capacity Mounted on
/devices/ramdisk:a 262M 240M 22M 92% /
/devices/pseudo/lofi@0:1
432M 377M 56M 88% /usr
/usr/lib/libc/libc_hwcap1.so.1
432M 377M 56M 88% /lib/libc.so.1
fd 0K 0K 0K 0% /dev/fd # *** 新增加 ***
ctfs 0K 0K 0K 0% /system/contract
proc 0K 0K 0K 0% /proc
mnttab 0K 0K 0K 0% /etc/mnttab
swap 43G 984K 43G 1% /etc/svc/volatile
objfs 0K 0K 0K 0% /system/object
bootfs 0K 0K 0K 0% /system/boot
sharefs 0K 0K 0K 0% /etc/dfs/sharetab
接着看_milestone/single-user_服务,同样先整理下它的依赖关系:
$ svcs -d milestone/single-user:default #查看single-user服务的依赖, 实际上single-user也依赖devices服务
online Jun_10 svc:/system/cryptosvc:default
online Jun_10 svc:/network/loopback:default
online Jun_10 svc:/milestone/devices:default
online Jun_10 svc:/system/keymap:default
online Jun_10 svc:/system/filesystem/minimal:default
online Jun_10 svc:/system/sysevent:default
online Jun_10 svc:/system/manifest-import:default
online Jun_10 svc:/system/identity:node
online Jun_10 svc:/milestone/network:default
这里single-user服务的依赖非常深,这里就只看system相关的文件系统的服务,这样看的会清楚些,先看filesystem/minimal的依赖:
svc:/system/filesystem/minimal
svc:/system/device/local # 服务以启动完成
svc:/network/datalink-management
svc:/system/filesystem/usr # 服务以启动完成
svc:/system/boot-archive
svc:/system/scheduler
svc:/system/filesystem/smartdc # 未完成
svc:/system/filesystem/usr
svc:/system/boot-archive
svc:/system/scheduler
从依赖来看,先分析_filesystem/smartdc_服务/lib/svc/manifest/system/filesystem/joyent-fs.xml找到脚本/lib/svc/method/fs-joyent,这里代码很多就不具体贴出来了,主要做了如下事情:
1、通过/usr/sbin/devfsadm -c disk命令创建/devices目录下所有磁盘设备文件并链接到/dev目录, 到这一步看看文件系统的挂载情况, 发现所有的磁盘设备都找到并挂载好了。
Filesystem Size Used Available Capacity Mounted on
/devices/ramdisk:a 262M 240M 22M 92% /
/devices/pseudo/lofi@0:1
432M 377M 56M 88% /usr
/usr/lib/libc/libc_hwcap1.so.1
432M 377M 56M 88% /lib/libc.so.1
fd 0K 0K 0K 0% /dev/fd
/devices 0K 0K 0K 0% /devices
/dev 0K 0K 0K 0% /dev
2、根据启动参数noimport看是否需要挂载zones pool的文件系统,如果需要则挂载如下设备:
Filesystem Size Used Available Capacity Mounted on
zones 5.2T 524K 4.3T 1% /zones
zones/cores/global 10G 19K 10G 1% /zones/global/cores
zones/var 5.2T 5.9G 4.3T 1% /var
zones/config 5.2T 66K 4.3T 1% /etc/zones
zones/opt 5.2T 19G 4.3T 1% /opt
zones/usbkey 5.2T 120K 4.3T 1% /usbkey
/usbkey/shadow 4.3T 120K 4.3T 1% /etc/shadow
/usbkey/ssh 4.3T 120K 4.3T 1% /etc/ssh
swap 44G 12K 44G 1% /tmp
swap 44G 12K 44G 1% /var/run
下面我们分析_filesystem/minimal_服务,通过/lib/svc/manifest/system/filesystem/minimal-fs.mxl我们看到,这个服务什么都没做只是定义了依赖。到这里run level s就启动完成所有服务启动,看看目前文件系统状态:
SmartOS 启动之: Run Level 2
从上面run level 1来看,基本的OS服务已经都启动了,在run level 2上启动的主要服务如下:
$ init 2
$ svcs |grep milestone
online 9:12:44 svc:/milestone/devices:default
online 9:14:17 svc:/milestone/single-user:default
online 9:12:43 svc:/milestone/name-services:default # 新增
online 9:12:43 svc:/milestone/name-services:default # 新增
online 9:14:38 svc:/milestone/multi-user:default # 新增
这里我们照葫芦画瓢同样通过svcs -d 来查看服务依赖然后去看对应脚本就可以。
SmartOS 启动之: Run Level 3
最后到run level 3的服务如下:
$ init 3
$ svcs |grep milestone
online 9:12:44 svc:/milestone/devices:default
online 9:14:17 svc:/milestone/single-user:default
online 9:12:43 svc:/milestone/name-services:default
online 9:12:43 svc:/milestone/name-services:default
online 9:14:38 svc:/milestone/multi-user:default
online 9:14:38 svc:/milestone/multi-user-server:default # 新增
这里就简单写下了,实在太长了,因为我没办法写短 🙂
SMF在SmartOS中扮演的重要角色
从上面对SmartOS的启动分析中我们可以看到,smf在其中的重要作用, 总结下SMF的提供的特性:
- 引入依赖关系。一个服务可以依赖另几个服务,满足不了条件就不起动或者暂停。
- 引入权限控制。打印机服务这种让linus都抓狂的服务,就让它在低权限跑去吧。
- 引入守护机制。死了帮你重启,重启不成就帮你暂停,以及暂停其他所有依赖这个服务。
- 用基于xml的配置文件,取代了简单的使用init.rc*文件夹以及文件名来组织各个服务。这个不用解释,因为init的那一套只能说是太原始了。
以上4点总结引用自李宇的blog, 他总结的非常好!最后想象下有了SMF这个东西,我们要定制一个基于Illumos内核的OS就不再像看起来那么的遥不可及,定义好run level和自己的服务依赖,专注在服务实现,把整个kernerl打包进去,build出ISO/USB/PXE的镜像。
转自:SmartOS Diskless Booting与SMF